Neural Networks and Natural Language Processing
by Jungo Kasai
Resources
Introduction
Neural Networks have been successful in many fields in machine learning such as Computer Vision and Natural Language Processing. In this post, we will go over applications of neural networks in NLP in particular and hopefully give you a big picture for the relationship between neural nets and NLP. Having such a big picture should help us read papers in the literature and understand the context more deeply.
Challenges and Resolutions
Applying neural networks to problems in Computer Vision is oftentimes straightforward. For example, we can represent each image in the MNIST dataset by a square of 28 by 28 pixels where each pixel takes on a real value. In NLP, there arises an issue how we represent words. With regards to this issue, word embedding techniques come into play. Perhaps, the dumbest thing we could do is to represent each word by a one-hot vector where all of the components are zero except one component being one. Namely, we represent each word by a unique index. This representation is not ideal because our vectors would be of the dimension equal to our vocabulary size, and moreover they would not preserve linguistically sensible structures. Since all of the one-hot vectors are orthogonal to each other by design, we would not be able to have any information in the distances among the vectors. Therefore, we want to have dense vector representation of words instead. There have been several techniques to vectorize words in English:
- WordNet at Princeton, starting in 1985
- Global Approach: (Pointwise Mutual Information) Matrix Factorization
- Local Apporach: Word2Vec by Mikolov et al. in 2013
- Global and Local: GloVe by Pennington, Socher, and Manning in 2014
WordNet is analogous to a dictionary in that humans manually annotate relations among words and group synonyms together. The other three methods all utilize English corpora; instead of manually encoding relations among words, we learn relations from text data.
While the WordNet approach obviously scales badly as we extend it to more words and even other languages, the learning approaches are more flexible. One simple way of learning word vectors from text data is to take some statistics in the data, construct a matrix with each row corresponding to each word and each column corresponding to each “context”, and factorize the matrix. The SVD is a common approach to do this. The context can have multiple ways to define, including frequency of co-ocurrence and the positive mutual information, which was proposed by Church and Hanks 1990. For a more extensive introduction to such methods of word vectorization, see Turney and Pantel 2010.
On the other hand, the Word2Vec algorithms are based on local information. The intuition is that we construct a shallow neural network that predicts words that appear around the word you are looking at (Skipgram) or the other way around (CBOW). Through this process, we obtain a vector representation for each word. We typically train this network by the stochastic gradient descent algorithm where the learning rate decays.
Images for Word2Vec from Rong 2016.
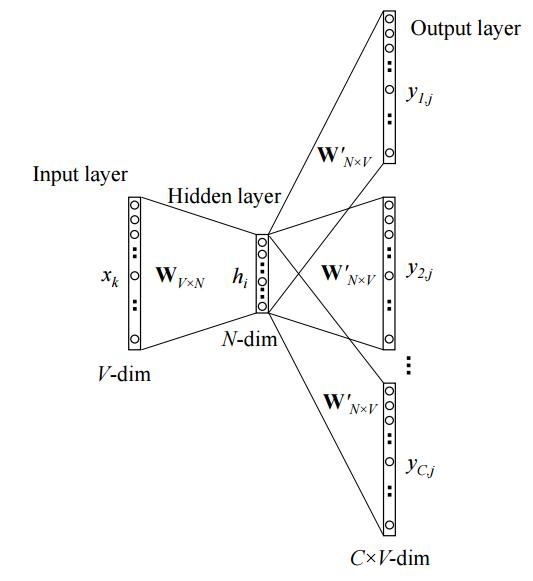
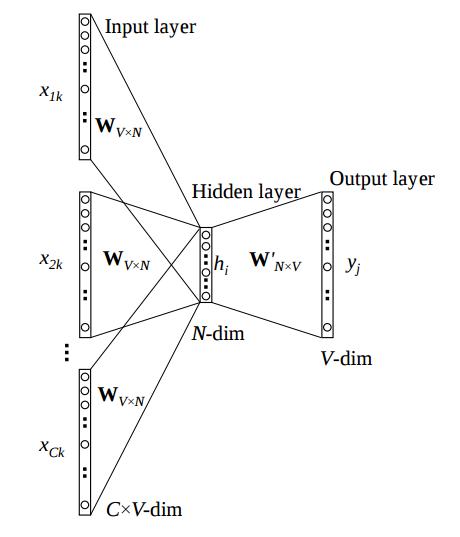
The Word2Vec algorithms are very successful and notably, Levy and Goldberg proposed a “global way” of looking at the Skipgram algorithm 1, though it requires the strong assumption of matrix reconstructability.
GloVe is intended to blend the global and local approaches by adding a global loss term to the objective function. It has achieved the state-of-the-art performances in the semantic and syntactic tasks.
As we saw above, there is plenty of work done on word embeddings. However, we still have an alternative to word embeddings as an ingredient to get fed into neural nets. As neural network architectures based on the Convolutional Neural Nets (CNNs) are getting attention in NLP 2, character-based encoding together with a CNN stands a chance where we let the network figure out which characters form a word instead of tokenizing the data beforehand. In this scheme, we can just represent each character in a one-hot vectorization fashion. This methodology is particularly appealing when dealing with languages whose tokenization is not cheap, such as Japanese and Chinese unlike English. In fact, a Japanese company reports that the character-based CNN achieved a great accuracy in classification of consumer reviews of restaurants 3. Even with regards to English incorporating character-based models into a machine translation model is one of the current areas of research 4.
Architectural Explorations
Given the ingredients above, one way to further proceed with neural-network-based approaches in NLP is to explore different architectures. Recurrent Neural Networks (RNNs) have been the most common architecture in neural nets for NLP since they are designed to deal with sequential data. In particular, the Long Short Term Memory (LSTMs) have served as a key building block. The LSTMs are designed to address the vanishing/exploding gradient problem of backpropagation through time steps by performing an additive update as opposed to a matrix-multiplicative update. Although the LSTMs have been established as a building block for neural-net-based approaches in NLP, the Gated Convolutional Neural Networks have recently achieved a better performance in language modeling with faster computation than the LSTMs 5. Moreover, attention mechanisms have also been explored in machine translation 6, question answering, sentiment analysis, and part-of-speech tagging 7.
Decomposition of Major Problems in NLP
Personally, I believe that decomposition of the major problems based on linguistic insights will play a key role in the future of neural nets in NLP. For example, with regards to the major task of syntactic syntactic parsing, people have prosed multiple formalisms to derive a tree for a sentence. One direct method is the dependency grammar and Google has provided neural-net-based dependency parser called Parsey McParseface. However, there are still different types of grammatical formalism: Tree Adjoining Grammar (TAG) introduced in Joshi et al. 1975 and Combinatory Categorial Grammar (CCG) introduced in Steedman 1987. In either of the two formalisms, parsing comprises two phases unlike the dependency grammar case. The first phase is supertagging where supertagging denotes a classification tasks into much richer categories than parts-of-speech. The second phase staples the assigned supertags together to derive a tree for each sentence. Both of the two phases can employ neural networks, and again there arise architectural questions. The CCG method has been successful to some degree 8. I am currently working on the TAG approach in my project.
Notes
In this post, we saw word embeddings as an ingredient for the use of neural nets in NLP. However, word embeddings serve other purposes in NLP and Computational Linguistics, including distributional semantics.
References
-
https://levyomer.files.wordpress.com/2014/09/neural-word-embeddings-as-implicit-matrix-factorization.pdf ↩
-
https://arxiv.org/pdf/1612.08083.pdf ↩
-
https://speakerdeck.com/bokeneko/tfug-number-3-rettyniokerudeep-learningfalsezi-ran-yan-yu-chu-li-hefalseying-yong-shi-li?slide=14 (Content in Japanese) ↩
-
https://github.com/lmthang/thesis/blob/master/thesis.pdf ↩
-
https://michaelauli.github.io/papers/gcnn.pdf ↩
-
https://arxiv.org/pdf/1409.0473.pdf ↩
-
https://arxiv.org/pdf/1506.07285.pdf (Dynamic Memory Networks) ↩
-
https://aclweb.org/anthology/D16-1181 ↩